
Thoughts·May 5, 2026
There’s a pattern in D2C that nobody talks about because ...

There’s a pattern in D2C that nobody talks about because it’s embarrassing for everyone involved.
A brand launches. It gets traction. It hits $1M ARR, then $5M. The founder is doing everything: product, ops, creative, customer service. At some point they can’t do it all anymore. They hire.
But they don’t just hire employees. They hire agencies.
One for performance marketing. One for creative. One for influencer. One for SEO. One for email. One for Amazon. One for the 3PL. The list grows proportional to revenue.
By the time a brand hits $20M, it’s running six to eight external vendors, each with their own account manager, their own reporting system, their own definition of success.
That’s not growth. That’s complexity disguised as growth. And it’s one of the most common reasons a DTC brand is not scaling the way the numbers should allow.
If you’re doing $10M in revenue and spending 30% on marketing — pretty standard for DTC — that’s $3M. A third of that probably goes to agencies. $1M a year in agency fees at that scale is not unusual.
What do you get for that $1M? Access to other people’s templates applied to your brand. Junior account managers who rotate every 18 months. Quarterly business reviews where the agency presents metrics that prove their own value.
The output scales with headcount. If the agency grows faster than your brand, they get sloppy. If they grow slower, you get deprioritized. Either way, you’re not their only client. You’re one of forty.
This is where the DTC brand growth plateau begins. Not in the product. Not in the market. In the infrastructure meant to drive growth. The founder sits in the middle, exhausted, trying to feed the specific soul of the brand into generic agency templates. Brand voice degrades at scale. Not because the team gets lazy. Because the team gets distributed across vendors who each have their own interpretation.
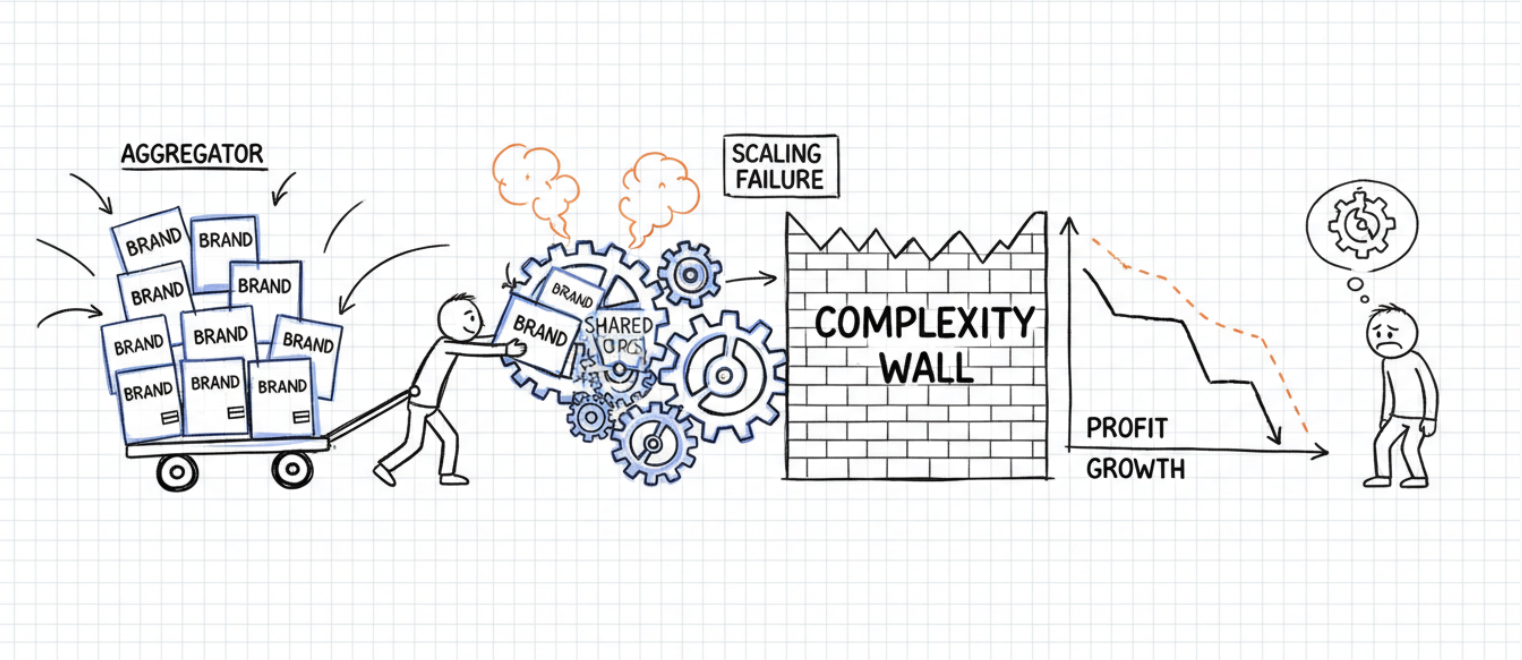
The rollup industry looked at this and thought they had the answer.
Acquire the brand. Standardize the playbook. Run the same agency stack across 200 brands. Standardize creatives. A/B test everything. Capture the scale.
Thrasio raised $3B. Berlin Brands Group. Branded. SellerX. Heroes. Perch. Most of them are either dead or restructured.
The thesis was seductive: these are just products. Commoditize the ops layer.
It didn’t work because the thesis was wrong about what a brand is.
A brand is not the product. A brand is not the supply chain. A brand is not the marketing stack. A brand is the specific way a specific founder sees a specific problem and tells the world about it. That’s not transferable.
This is exactly why DTC brands fail to scale under the rollup model. When Thrasio acquired a brand, they kept the product and the supply chain. They lost the part that made customers care. They replaced a founder who knew every customer complaint by name with an operations manager reading dashboards. CAC went up. Retention went down. The story got blander.
What they were really buying was the tail end of the brand’s energy: the period where customer loyalty carries the business before new customers notice something is off.
You can’t put the same creative playbook on a skincare brand built by a Black founder for textured hair and a performance supplement brand built by a gym rat. They need different voices, different aesthetics, different communities, different ways of being in the world.
The agencies knew this, to be fair. “We do bespoke creative for each client,” they all say. But bespoke across forty clients means bespoke when there’s time. Which means not very bespoke.
Here’s the actual problem. Every DTC brand at $5M to $50M is running roughly the same stack:
The internal team? Usually 5 to 15 people. A CEO who’s also the product person. A head of brand who’s also the social media manager. An ops person who’s also the customer service escalation.
The agencies are where the actual work happens. And agencies are, by definition, not specialized to the brand. They’re specialized to the category.
“We work with beauty brands” means they’ve worked with enough beauty brands to know the common patterns. It doesn’t mean they understand what makes your beauty brand different. It usually means they’re going to apply the pattern they already know.
Brands need to sound different. Feel different. Look different. But almost all of them hire the same bunch of agencies, hire mostly the same type of people, and run the same quarterly campaign cycle.
The result is a sector where brand differentiation is supposed to be the competitive advantage, but the infrastructure that creates brand expression is almost completely commoditized.
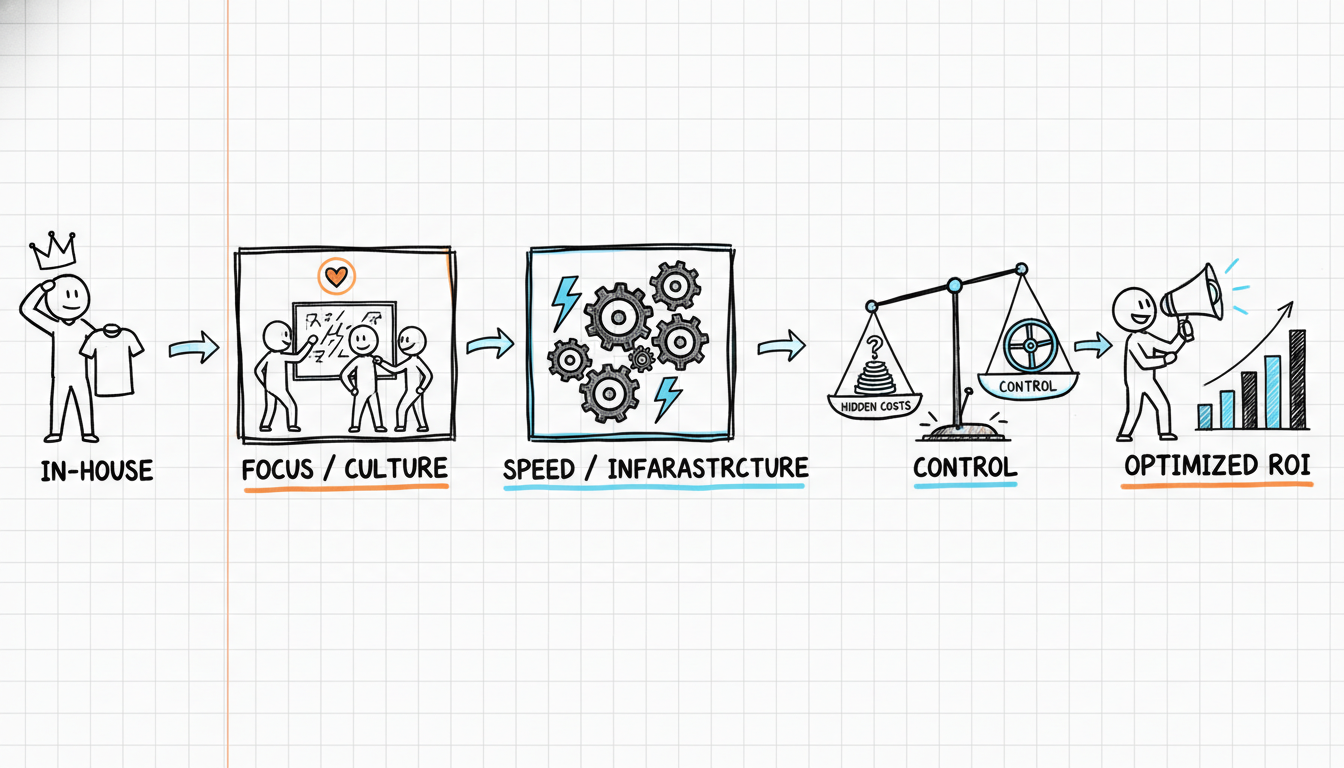
Every founder eventually reaches this crossroads. Do you keep the agencies, bring it in-house, or find a third path?
The in-house vs agency debate has been going on for years, but it usually gets framed wrong. The question isn’t which model is cheaper or faster. The question is which model actually holds the brand’s accumulated knowledge over time.
Agencies own the output, not the learning. Every brief you give them, every campaign result, every insight about what your customers respond to: that stays with the agency. When the account manager leaves (and they do, usually around 18 months in), you start over. When you eventually switch agencies, you start over again.
That’s the structural failure underneath the DTC marketing in-house vs agency decision. In-house teams are expensive and slow to build. But they hold the learning. Agencies are faster to access but leak knowledge constantly.
Neither is the answer the way most brands are running them.
What changed in 2024 and 2025 wasn’t that AI got smart enough to do creative. It was that AI got smart enough to understand context.
There’s a difference. Earlier AI tools could generate a product description. That’s intelligence: following rules to produce an output. The model knows what product descriptions look like. It generates one.
What changed is that you can now give a model the brand’s entire content history: every email, every campaign, every product brief, every customer complaint, every founder interview, and ask it to produce something that sounds like this brand specifically.
That’s not intelligence. That’s judgment. Judgment built on complete context.
The Sequoia thesis on services gets this right. The shift from copilot to autopilot isn’t about the model getting smarter in general. It’s about specific context getting captured properly, and the model being able to apply it without human translation every single time.
For founders trying to figure out how to scale a DTC brand, the bottleneck has never been creative production or media buying. It’s been context. The brand’s full understanding of itself: what it sounds like, what works, what doesn’t, and why. That context has always existed in fragments, spread across agencies, Slack threads, and people’s heads.
None of this lives in any system. None of it is accessible. None of it compounds.
That’s the actual bottleneck. Not creative production. Not media buying. Context.
Every task in a brand operation sits somewhere on a spectrum from pure intelligence to pure judgment.
Intelligence work: generating product descriptions, resizing ad creative, writing email subject line variants, pulling competitive pricing data, formatting a media plan, scheduling posts.
Judgment work: deciding which product category to enter next, reading a community’s mood and knowing when not to run a campaign, identifying that a specific influencer partnership is off-brand even though the numbers look right, choosing to lean into a narrative before the data proves it.
Agencies charge judgment rates for intelligence work. They have to. Their cost structure: account managers, creative directors, strategists, doesn’t compress. So they bill for the whole package even when 80% of the actual work is rules-following.
This is where the margin in the agency model has always come from. Not from being irreplaceable. From the inconvenience of the alternative.
The alternative used to be: hire internally. Expensive, slow, and you take on all the coordination cost yourself.
Now the alternative is something different.
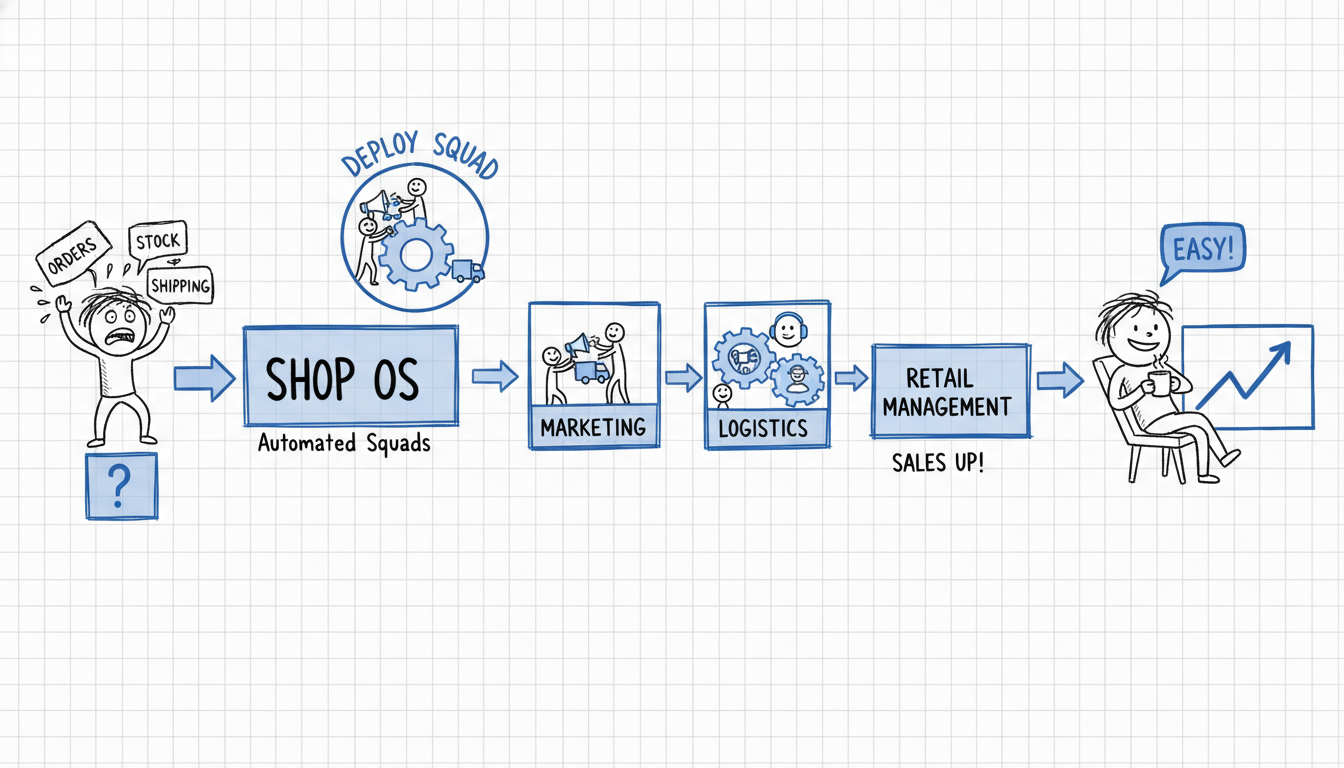
ShopOS is built around one idea: capture the context, then let the agents run.
It’s not an agency. It’s not a SaaS tool. It’s a squad: a small team of humans paired with a stack of specialized agents, assembled around a single brand, running as if they’re an internal team.
The squad runs an Openclaw implementation. Openclaw is ShopOS’s intake process: a structured set of sessions that extracts the brand’s full context. Every existing campaign. Every SKU. Every customer segment. Every piece of language the brand has ever used publicly.
The founder doesn’t fill out forms. They talk. The system transcribes, structures, and stores everything. Four to six hours across a week.
At the end of month one, the brand has a Brand Memory. Not a Notion doc. Not a Figma moodboard. A live knowledge graph: every decision the brand has made, linked to the context that made it. Product positioning linked to competitor analysis linked to customer quotes linked to campaign performance.
Most brands have never done this. They’ve accumulated years of decisions that live in Slack threads, email chains, and individual people’s heads. Openclaw makes it concrete. And once it’s concrete, the agents can use it.
Six agents. Each with a defined scope, each pulling from Brand Memory when they work.
A human team at a $20M brand would have a head of each of these functions. The agency model parcels each out to a different vendor. ShopOS collapses it into one system. The orchestrator manages the handoffs between agents.
The human squad (usually two to three people) doesn’t execute the work. They steer it. Review, refine, override, escalate. Their job is judgment. The agents do the execution.
One of the most underrated parts of this is ambient capture.
The Mac intern is a background application running on the brand team’s machines. It transcribes meetings, records decisions, and surfaces them to the agent stack in real time.
When a founder gets off a call with a supplier and says “we’re moving the summer launch from June to April,” that’s captured. Linked to the relevant campaigns. Surfaced to Monica when she’s building the next creative brief. Surfaced to Erlich when he’s modeling media spend.
Most agencies find out about launch changes two weeks late, through a forwarded email. Two weeks of planning gets thrown out. The Mac intern closes that gap to hours.
This is not a feature. It’s a structural change in how information flows inside a brand operation.
Every night, the agent stack runs. While the brand team sleeps.
A typical overnight batch for a fashion brand: 200 product descriptions refreshed against current performance data. 40 email variants generated for the next month’s campaigns. A competitive intelligence report from Iris, ShopOS’s research agent, scanning competitor drops, pricing shifts, and community sentiment. 15 UGC brief variations for upcoming influencer outreach. A performance summary with recommended budget shifts for the week ahead.
The brand team wakes up to a review queue. Not a blank page. Not a list of tasks. A queue of outputs, each with a confidence score and a reason for the recommendation. They approve, reject, refine, or send back for rework.
This is not automation. Automation implies the human is removed. This is amplification: a small team moving at the speed of a large one.
Spaces are structured workflows the brand team can run on demand. Think of them as deterministic multi-step processes that the brand defines once and reuses.
A brand might build a Space for new product launch sequencing: intake the product brief, generate the positioning, draft the email campaign, brief the UGC, generate paid creative copy, and output a complete launch package. The brand team reviews at each stage. The Space handles the execution between stages.
Another brand might build a Space for influencer vetting: intake a creator’s handle, run them through audience analysis, brand alignment check, past performance benchmarks, and output a recommendation with a suggested brief if they pass.
Spaces make repeatable work reliable. Once a process is in a Space, it doesn’t degrade. It doesn’t depend on who’s in the seat. It runs the same way every time, at whatever speed the brand needs.
The thing that makes this compound over time is Loops.
Loops is the experimentation layer. Three modes.
Before running anything live, you simulate. The agent stack models expected performance based on Brand Memory, past campaign data, and current market conditions. You see projected CAC, ROAS, and engagement before spending a dollar. The simulation gets more accurate as Brand Memory grows.
You set the loop to watch. Run a campaign. The agent tracks performance in real time, surfaces anomalies, flags underperforming creative, identifies winning patterns. You’re not watching dashboards. You’re watching a system that already knows what good looks like for this specific brand, because it’s learned from everything the brand has run before.
Structured A/B testing across any variable. Not just copy versus copy. Hook versus hook. Offer versus offer. Audience segment versus segment. The test design comes from the agent. The human approves it. The results feed back into Brand Memory.
Here’s the important part: every override teaches the system something. When Monica generates thirty creative variations and the founder approves three, that signal goes back into Brand Memory. Monica gets better. Next cycle, the top three are more likely to already be the right three.
The judgment loop tightens. And tighter judgment loops mean fewer iterations, lower CAC, better retention.
Over time, Brand Memory becomes the single most valuable asset the brand owns. Not the products. Not the customer list. The codified understanding of what works for this specific audience with this specific brand voice, accumulated through real campaigns, real feedback, real outcomes.
That’s the moat. Not the model. The data about judgment.
January: Quarterly planning session with three agencies. Each presents their strategy. Founder spends three days aligning them. One agency uses different attribution methodology than the other two. Nobody can agree on the numbers.
February: Creative production begins. Briefing takes two weeks because the creative agency needs context that doesn’t exist in any document. The founder sits for three calls explaining the brand, again, to the same agency they’ve worked with for two years.
March: First campaign goes live. Performance is okay. The data is split across three dashboards: the agency’s reporting tool, Meta’s ads manager, Klaviyo. The numbers don’t reconcile.
April: Founder notices a UGC video performing three times better than everything else. Flags it to the creative agency. Takes four weeks to brief a new batch of similar content.
May: Summer collection planning starts. Supply chain delay means the launch window shifts by six weeks. Agencies find out late. Three weeks of media planning has to be redone. Nobody bills the brand for it. Nobody mentions that this has happened three times before.
June to August: Peak execution. The brand is spending $500K/month across channels. The founder is in twelve agency calls per week. Every week someone needs a decision that only the founder can make. The founder’s calendar is full. Strategic thinking is zero.
September: Post-peak analysis. The agencies send their own reports. None of them agree. The performance marketing agency says ROAS was 3.2. The brand team’s internal calculation says 2.1. Nobody resolves the discrepancy. The founder moves on.
October: Q4 planning starts. Same process. Same agencies. Same cycle.
December: Post-Q4 debrief exists only as a slide deck that nobody will look at again. Three months of campaign data that no one has time to synthesize. The team goes on holiday. January: start again.
Total agency spend: $1.8M. Internal headcount for brand functions: 8 people. Founder’s strategic output: near zero, consumed by coordination.
Nothing learned from this year that automatically applies to next year.
January: Openclaw implementation. Four sessions across two weeks. Brand Memory built from 24 months of campaign history, the full product catalog with positioning notes, customer segments, and brand voice guidelines derived from 400 pieces of existing content. The agents have full context.
February: First overnight batch runs. 180 product descriptions refreshed. Email calendar for Q1 generated. Monica builds the creative strategy for the spring collection. The founder reviews and approves in three hours. In 2023, this took three agency calls and two weeks of back-and-forth.
March: Spring campaign goes live. Loops set to Listen. Day three: Gavin flags that one hook in the UGC is pulling 40% lower CTR than projected. Monica generates six replacement hooks. Founder approves two. New content is live within 48 hours. In 2023, this discovery would have taken four weeks and a separate briefing cycle.
April: Summer planning starts. Dinesh flags the supply chain delay directly in the campaign timeline, because the Mac intern captured the supplier call two weeks ago. The campaign plan adjusts automatically. No wasted work.
May: Media strategy for summer is done in a week. Erlich models three budget scenarios. Loops set to Simulate. The model predicts a CAC of $28 to $32 for the target audience across the planned channel mix. Campaign goes live. Actual CAC: $31. The model was right.
June to August: Peak season. The brand team of four people is running at the output of a twelve-person team. The founder is in three internal syncs per week, not twelve agency calls. Strategic thinking is back on the calendar. The founder uses that time to build the relationship with a manufacturing partner that opens up the next product category.
September: Post-peak analysis is done automatically. One report. One source of truth. Every channel. Every test. Every outcome. Brand Memory is updated.
October: Q4 planning takes four days, not four weeks. The agent stack drafts the full holiday campaign strategy from Brand Memory. The founder’s job is to review, modify, and decide on the things that actually require judgment: the bet on the new product category, the pricing decision on the core SKU, the influencer partnership that’s off-model but feels right.
December: Brand Memory has grown by a full year of real data. Next year’s simulations will be sharper. The moat is wider than it was in January. The brand knows more about itself: structurally, not just anecdotally, than it did twelve months ago.
Total ShopOS spend: $36K (managed services at $3K/month with $10K guaranteed outcomes built into the structure). Internal headcount: 4. Founder’s strategic output: real.
Every decision from this year feeds the next year. The system learns. The advantage compounds.
In the old model, the CEO of a $15M brand was a coordinator. Keeping agencies aligned. Keeping the team from drowning. Keeping the product pipeline moving.
In the ShopOS model, the CEO is an architect. They define what the agents optimize for. They set the brand’s north star. They make the ten decisions per month that actually require them specifically. They spend the rest of their time on the things only founders can do: customer relationships, product vision, capital, culture.
That shift is not cosmetic. It changes what’s possible for the brand. A founder who has cognitive bandwidth is a different kind of founder than one who’s spending it on agency coordination.
The question is not whether you can afford ShopOS. The question is what it costs to keep running the 2023 playbook while your competitors don’t.
The brand still needs a founder. Still needs a human with taste, judgment, and domain expertise. ShopOS doesn’t change that.
Monica can generate 200 creative variations. The founder picks the five that feel right. Monica gets better from that signal. Next time, the top five are more likely to already be the right five. But the signal still needs to come from a human who understands why the brand exists.
Jared handles 80% of community management: the standard responses, the thank-yous, the order issue resolutions. The founder handles the 20% that matters: the customer who’s been buying for three years and had a bad experience, the influencer who wants a real relationship, the partnership that needs a human counterparty.
This is the agentcy model applied to brand. The human team holds the judgment and the accountability. The agents hold the execution and the memory.
The three things that made rollups fail: founder insight, brand voice, community. Those are the three things ShopOS is designed to capture and protect. Openclaw codifies the insight. Brand Memory preserves the voice. Jared supports the community without replacing the human relationships that built it.
The agents amplify what’s there. They don’t invent what isn’t.
Two things happened simultaneously.
First, the models crossed a threshold. Not in general intelligence, but in contextual reasoning. You can give a model complete brand context and get outputs that are genuinely brand-specific, not category-generic.
Second, the infrastructure to capture and structure that context got practical. Transcription is accurate. Knowledge graphs are buildable at brand scale. The system exists to hold Brand Memory and make it accessible to agents in real time.
Before these two things were true, AI for brands meant prompt-and-pray. “Write me a product description for this face cream.” The model didn’t know the brand. It didn’t know the customer. It knew face creams in general. Output was average.
Now, with Brand Memory, the model knows: this face cream is for customers who’ve tried twenty products and still haven’t found one that works. The language that converts is not about the ingredient list. It’s about the relief of finally finding something that does. The founder figured this out in year two. It’s in the memory graph. The model uses it every time.
That’s the actual unlock. Not the model. The context.
The next five years will split DTC brands into two categories: those whose understanding of themselves compounds, and those whose understanding resets every eighteen months when the account manager leaves.
If your DTC brand is not scaling the way you expect, the answer is rarely in the channel or the creative. It’s in the structure. Who owns the learning? Where does the knowledge live? What happens when the agency relationship ends?
Brand Memory is not just an operational advantage. It’s a strategic one. A brand that knows, structurally and not just anecdotally, what language converts at which stage of the funnel, what creative hooks work for which customer segment, what pricing signals trigger purchase and which trigger hesitation, has a fundamentally different kind of asset than a brand that’s been running the same gut-feel playbook for six years.
That knowledge, accumulated through real campaigns and real loops, and made accessible to agents who can apply it without human translation, is worth more than any individual creative or any single campaign.
It’s also the thing that agencies have structurally never been able to build for their clients. Because they own the output, not the learning. The learning stays with the agency when the relationship ends. The brand starts over.
With Brand Memory, the learning stays with the brand. Forever. And it gets sharper every quarter.
The headcount trap is real. The agency trap is real. The rollup trap was real. There’s a way out of all three, and it doesn’t require building a 50-person team or selling the company.
Most brands already have everything ShopOS needs to get started. The campaign history is there. The founder knowledge is there. The customer data is there. None of it is connected, none of it compounds, and none of it survives the next agency transition.
That changes in month one.
If you are serious about figuring out how to scale a DTC brand without rebuilding your entire team or handing another agency a blank retainer, the conversation starts at ShopOS.ai
No, agencies own the output, ShopOS builds Brand Memory that stays with you. Every campaign, every test, every insight compounds into an asset you own permanently.
The Mac intern captures decisions in real time as they happen, supplier calls, strategy shifts, launch changes and updates the knowledge graph automatically. Brand Memory isn’t a document you maintain; it rewrites itself as the brand does.
Every founder override is a signal. When Monica generates thirty creatives and you approve three, that judgment feeds back into Brand Memory. The system gets more specific to your brand with every cycle, not less.
Loops runs a Simulate pass first, modeling projected CAC and ROAS against Brand Memory before spending a dollar. You’re not flying blind on new channels; you’re stress-testing them against everything the brand already knows about its audience.
Openclaw is built for exactly this, fragmented history across agencies, Slack threads, and platforms. The value isn’t in clean data; it’s in connecting decisions to outcomes that have never been linked before.
The squad’s job is judgment and steering, not execution, so throughput scales with the agents, not the headcount. If the review queue backs up, that’s a signal to expand Spaces or adjust the overnight batch scope, not to hire.